如果你关心最优化(Optimization),你一定听说过一类叫作“信赖域(Trust Region)”的算法。在本文中,我将讲述一下信赖域算法与一维搜索的区别、联系,以及信赖域算法的数学思想,实现过程。
【1】信赖域算法与一维搜索算法的区别、联系
最优化的目标是找到极小值点,在这个过程中,我们需要从一个初始点开始,先确定一个搜索方向  ,在这个方向上作一维搜索(line search),找到此方向上的可接受点(例如,按两个准则的判定)之后,通过一定的策略调整搜索方向,然后继续在新的方向上进行一维搜索,依此类推,直到我们认为目标函数已经收敛到了极小值点。
,在这个方向上作一维搜索(line search),找到此方向上的可接受点(例如,按两个准则的判定)之后,通过一定的策略调整搜索方向,然后继续在新的方向上进行一维搜索,依此类推,直到我们认为目标函数已经收敛到了极小值点。
这种通过不断调整搜索方向,再在搜索方向上进行一维搜索的技术被很多很多算法采用,也取得了很实际的工程意义,但是,我们非要这样做不可吗?有没有另外一种途径,可以不通过“调整搜索方向→进行一维搜索”的步骤,也能求得极小值点?当然有,这就是信赖域算法干的好事。
文章来源:http://www.codelast.com/
为了说明这两种途径所实现的算法的区别和联系,请允许我做一个可能不太恰当,但是比较形象的比喻:
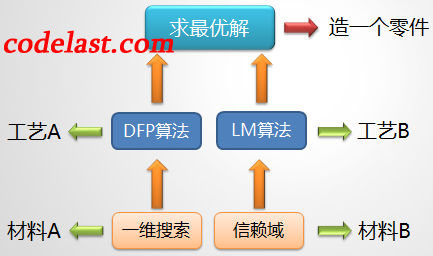
上图表述的是:如果把求最优解的过程比喻为“造一个零件”的过程的话,那么,使用一维搜索的那些算法和信赖域算法就像是两种不同的工艺,它们分别使用不同的技术(一维搜索&信赖域方法)——即两种不同的材料作为达成最终目标的基础。
作为一个了解最优化理论并不多的人,我从我看到过的书得到的感受就是:相比使用一维搜索的那一类算法,貌似信赖域算法们的应用还不够那么多。当然这仅仅是个人感觉,勿扔砖...
文章来源:http://www.codelast.com/
【2】信赖域算法的基本思想
信赖域和line search同为最优化算法的基础算法,但是,从“Trust Region”这个名字你就可以看出,它是没有line search过程的,它是直接在一个region中“search”。
在一维搜索中,从  点移动到下一个点的过程,可以描述为:
点移动到下一个点的过程,可以描述为: 
此处  就是在
就是在  方向上的位移,可以记为
方向上的位移,可以记为 
而信赖域算法是根据一定的原则,直接确定位移 ,同时,与一维搜索不同的是,它并没有先确定搜索方向 。如果根据“某种原则”确定的位移能使目标函数值充分下降,则扩大信赖域;若不能使目标函数值充分下降,则缩小信赖域。如此迭代下去,直到收敛。
文章来源:http://www.codelast.com/
关于这种寻优的方法,我这里又有一个比喻,希望能帮助你理解:
①可以先定一个方向,比如先向西走,走着走着发现方向有点不对(人民广场应该是时尚地标啊,怎么越走感觉越郊区了呢),就调整一下方向,变成向东南方向走,诸如此类。
文章来源:http://www.codelast.com/
【3】信赖域算法的数学模型
前面说了,根据一定的原则,可以直接确定位移,那么,这个原则是什么呢?
答:利用二次模型模拟目标函数
 ,再用二次模型计算出位移
,再用二次模型计算出位移  。根据位移 可以确定下一点
。根据位移 可以确定下一点  ,从而可以计算出目标函数的下降量(下降是最优化的目标),再根据下降量来决定扩大信赖域或缩小信赖域。
,从而可以计算出目标函数的下降量(下降是最优化的目标),再根据下降量来决定扩大信赖域或缩小信赖域。那么,我该如何判定要扩大还是缩小信赖域呢?为了说明这个问题,必须先描述信赖域算法的数学模型:
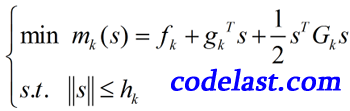
文章来源:http://www.codelast.com/
第一个式子就是我们用于模拟目标函数的二次模型,其自变量为
,也就是我们要求的位移。  为梯度,
为梯度,  为Hesse矩阵,袁亚湘的书上说,如果Hesse矩阵不好计算,可以利用“有限差分”来近似 (不好意思我不懂),或者用拟牛顿方法来构造Hesse矩阵的近似矩阵。
为Hesse矩阵,袁亚湘的书上说,如果Hesse矩阵不好计算,可以利用“有限差分”来近似 (不好意思我不懂),或者用拟牛顿方法来构造Hesse矩阵的近似矩阵。第二个式子中的
 是第
是第  次迭代的信赖域上界(或称为信赖域半径),因此第二个式子表示的就是位移要在信赖域上界范围内。此外,第二个式子中的范数是没有指定是什么范数的,例如,是2-范数还是∞-范数之类的(在实际中都有算法用这些范数)。
次迭代的信赖域上界(或称为信赖域半径),因此第二个式子表示的就是位移要在信赖域上界范围内。此外,第二个式子中的范数是没有指定是什么范数的,例如,是2-范数还是∞-范数之类的(在实际中都有算法用这些范数)。文章来源:http://www.codelast.com/
现在又回到了上面的问题:我该如何判定要扩大还是缩小信赖域呢?通过衡量二次模型与目标函数的近似程度,可以作出判定:
第
次迭代的实际下降量为: 
第
次迭代的预测下降量为: 
定义比值:

这个比值可以用于衡量二次模型与目标函数的近似程度,显然
 值越接近1越好。
值越接近1越好。
由此,我们就可以给出一个简单的信赖域算法了。
文章来源:http://www.codelast.com/
【4】信赖域算法的步骤
一个考虑周全的信赖域算法可能非常麻烦,为了说明其步骤,这里只说明基本的迭代步骤:
-
从初始点
 ,初始信赖域半径
,初始信赖域半径  开始迭代
开始迭代 -
到第 步时,计算 和
-
解信赖域模型,求出位移 ,计算

-
若
 ,说明步子迈得太大了,应缩小信赖域半径,令
,说明步子迈得太大了,应缩小信赖域半径,令 
-
若
 且
且  ,说明这一步已经迈到了信赖域半径的边缘,并且步子有点小,可以尝试扩大信赖域半径,令
,说明这一步已经迈到了信赖域半径的边缘,并且步子有点小,可以尝试扩大信赖域半径,令 
-
若
 ,说明这一步迈出去之后,处于“可信赖”和“不可信赖”之间,可以维持当前的信赖域半径,令
,说明这一步迈出去之后,处于“可信赖”和“不可信赖”之间,可以维持当前的信赖域半径,令 
-
若
 ,说明函数值是向着上升而非下降的趋势变化了(与最优化的目标相反),这说明这一步迈得错得“离谱”了,这时不应该走到下一点,而应“原地踏步”,即
,说明函数值是向着上升而非下降的趋势变化了(与最优化的目标相反),这说明这一步迈得错得“离谱”了,这时不应该走到下一点,而应“原地踏步”,即  ,并且和上面 的情况一样缩小信赖域。反之,在
,并且和上面 的情况一样缩小信赖域。反之,在  的情况下,都可以走到下一点,即
的情况下,都可以走到下一点,即 
【5】最重要的一种信赖域算法:Levenberg-Marquardt算法
当信赖域模型中的范数
 取2-范数时(即
取2-范数时(即  ),就得到了Levenberg-Marquardt算法(简称LM算法)的数学模型:
),就得到了Levenberg-Marquardt算法(简称LM算法)的数学模型: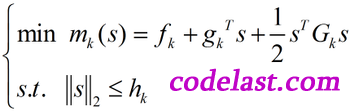
具体请看这里。
文章来源:http://www.codelast.com/
【6】信赖域算法的收敛性
信赖域算法具有整体收敛性。这个证明我没看(太长了),此处略。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):

有限差分是偏微分方程的方法,差分是函数值的差
“若 rk≤0.25 ,说明步子迈得太大了,应缩小信赖域半径” 这种情况应该是预测的函数下降的比实际函数大吧,这时要缩小信頼域半径,但是前面有一句“若不能使目标函数值充分下降,则缩小信赖域”,感觉这里是不是矛盾?
我也觉得可能是写反了,刚开始学习,并不太懂哈哈还是傻瓜的声援你一下,说不定作者看到会解释
我觉得并不是矛盾。预测的下降比实际的下降大很多,说明你预测的太远了,要收回来。所以要缩小信赖域半径。这里的rk<=0.25不就是“不能使目标函数值充分下降”的体现吗?
Rk1表示预测比实际下降的快,信赖域要减小