在最优化的领域中,这“法”那“法”无穷多,而且还“长得像”——名字相似的多,有时让人觉得很迷惑。
在自变量为一维的情况下,也就是自变量可以视为一个标量,此时,一个实数就可以代表它了,这个时候,如果要改变自变量的值,则其要么减小,要么增加,也就是“非左即右“,所以,说到“自变量在某个方向上移动”这个概念的时候,它并不是十分明显;而在自变量为n(n≥2)维的情况下,这个概念就有用了起来:假设自变量X为3维的,即每一个X是(x1, x2, x3)这样的一个点,其中x1,x2和x3分别是一个实数,即标量。那么,如果要改变X,即将一个点移动到另一个点,你怎么移动?可以选择的方法太多了,例如,我们可以令x1,x2不变,仅使x3改变,也可以令x1,x3不变,仅使x2改变,等等。这些做法也就使得我们有了”方向“的概念,因为在3维空间中,一个点移动到另一个点,并不是像一维情况下那样“非左即右”的,而是有“方向”的。在这样的情况下,找到一个合适的”方向“,使得从一个点移动到另一个点的时候,函数值的改变最符合我们预定的要求(例如,函数值要减小到什么程度),就变得十分有必要了。
前奏已经结束,下面进入正题。
【1】最速下降法(或:梯度法)
加注:我又写了一篇关于最速下降法的文章,更详细,请看这里。
很形象,也许你的脑子里一闪而过的,就是:取可以让目标函数值最快速“下降”的方法?差不多是这么回事。严谨地说:以负梯度方向作为极小化方法的下降方向,这种方法就是最速下降法。
为什么是负梯度方向使目标函数值下降最快?以前我也只是死记硬背,背出来的东西虽然有用,终究还是令人糊涂的。所以有必要写出它”为什么“的理由:
我们正在讨论的是”n维空间中的一个点移动到另一个点之后,目标函数值的改变情况“,因此,先直接写出代表最终的目标函数值的数学表达式:
![]()
![]() :代表第k个点的自变量(一个向量)。
:代表第k个点的自变量(一个向量)。
![]() :单位方向(一个向量),即 |d|=1。
:单位方向(一个向量),即 |d|=1。
![]() :步长(一个实数)。
:步长(一个实数)。
![]() :目标函数在Xk这一点的梯度(一个向量)。
:目标函数在Xk这一点的梯度(一个向量)。
![]() :α的高阶无穷小。
:α的高阶无穷小。
显然,这个数学表达式是用泰勒公式展开得到的,样子有点难看,所以对比一下自变量为一维的情况下的泰勒展开式
![]()
就知道多维的情况下的泰勒展开式是怎么回事了。
在[1]式中,高阶无穷小可以忽略,因此,要使[1]式取到最小值,应使![]() 取到最小——这是两个向量的点积(数量积),何种情况下其值最小呢?来看两向量
取到最小——这是两个向量的点积(数量积),何种情况下其值最小呢?来看两向量![]() 的夹角θ的余弦是如何定义的:
的夹角θ的余弦是如何定义的:
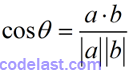
假设向量![]() 与负梯度
与负梯度![]() 的夹角为θ,我们便可求出点积
的夹角为θ,我们便可求出点积![]() 的值为:
的值为:
![]()
可见,θ为0时,上式取得最小值。也就是说,![]() 取
取![]() 时,目标函数值下降得最快,这就是称负梯度方向为“最速下降”方向的由来了。
时,目标函数值下降得最快,这就是称负梯度方向为“最速下降”方向的由来了。
最速下降法的收敛性:对一般的目标函数是整体收敛的(所谓整体收敛,是指不会非要在某些点附近的范围内,才会有好的收敛性)。
最速下降法的收敛速度:至少是线性收敛的。
【2】牛顿法
上面的最速下降法只用到了梯度信息,即目标函数的一阶导数信息,而牛顿法则用到了二阶导数信息。
在![]() 点处,对目标函数进行泰勒展开,并只取二阶导数及其之前的几项(更高阶的导数项忽略),得:
点处,对目标函数进行泰勒展开,并只取二阶导数及其之前的几项(更高阶的导数项忽略),得:
![]()
![]() :目标函数在Xk这一点的梯度(一个向量)。
:目标函数在Xk这一点的梯度(一个向量)。
![]() :目标函数在Xk这一点的Hesse矩阵(二阶导数矩阵),这里假设其是连续的。
:目标函数在Xk这一点的Hesse矩阵(二阶导数矩阵),这里假设其是连续的。
由于极小值点必然是驻点,而驻点是一阶导数为0的点,所以,对 r(X) 这个函数来说,要取到极小值,我们应该分析其一阶导数。对X求一阶导数,并令其等于0:
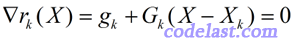
当Gk的逆矩阵存在,也即Gk为非奇异矩阵的时候,将上式两边都左乘Gk的逆矩阵Gk-1,得:
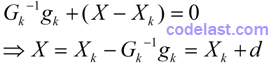
到了这一步,已经很明显了。这个式子表达了下一点的计算方法:Xk在方向d上按步长1(1×d = d)移动到点X。所以我们知道方向d怎么求了:
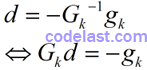
如果你觉得上式有点奇怪:为什么都得到了d的表达式,还要再弄出一个Gkd=-gk?那么我说:因为在实际应用中,d并不是通过Gk-1与gk相乘来计算出的(因为我们并不知道逆矩阵Gk-1是什么),而是通过解方程组Gkd=-gk求出的。这个解方程组的过程,其实也就可能是一个求逆矩阵的过程。关于解此方程组的方法,可以参考这一篇文章。关键时刻,概念清晰很重要。
有人说,那么方程组可能无解呢?没错,方程组可能是奇异的,在这种情况下,就需要用到其他的修正技术,来获取搜索方向了,本文不谈。
上面关于牛顿法的各种推导可能让你觉得杂乱无章,但实际上它们就是牛顿法的基本步骤:每一步迭代过程中,通过解线性方程组得到搜索方向,然后将自变量移动到下一个点,然后再计算是否符合收敛条件,不符合的话就一直按这个策略(解方程组→得到搜索方向→移动点→检验收敛条件)继续下去。
牛顿法的收敛性:对一般问题都不是整体收敛的(只有当初始点充分接近极小点时,才有很好的收敛性)。
牛顿法的收敛速度:二阶收敛。因此,它比最速下降法要快。
【3】共轭方向法
加注:我又写了一篇关于共轭方向法的文章,更详细,请看这里。
上面的方法,前、后两次迭代的方向并没有特别的相关要求,而共轭方向法则有了——它要求新的搜索方向与前面所有的搜索方向是共轭的。由于搜索方向是向量,所以也就是说,这些向量是满足共轭条件的:
![]()
其中,m≠n,dm和dn分别为两个向量(搜索方向),G为对称正定矩阵。
对于“共轭”,我有一个自己“捏造”出来的说法,来帮助你记忆它的含义:看到“共轭”,就想到“共遏”,即“互相遏制”,这不,两个向量中间夹着一个矩阵互相发力,结果谁也占不到便宜——积为0。
共轭方向法也是只利用了目标函数的梯度信息,即一阶导数信息,不用计算Hesse矩阵,使得其计算量比牛顿法小很多。
但是,怎么在每一步迭代的过程中,都得到若干个两两共轭的搜索方向?Powell共轭方向集方法是一个选择,它可以构造出若干个两两共轭的方向。不过,它本身也有一些缺陷:在构造共轭方向的过程中,各方向会逐渐变得线性相关,这就达不到“共轭”的要求了。所以,有很多种对Powell算法进行修正的策略被人们应用到了实际场景中,现在说到Powell方法,应该或多或少都包含了那些修正策略吧(我的感觉)。
特别值得一提的是,在共轭方向法中,新搜索方向的确定,是要满足“下降”条件的,即方向与梯度之积<0:
![]()
是不是意味着目标函数值下降量越大,这个方向就越可取呢?不是。在人们已经发现的修正Powell算法的有效方法中,有一种方法是舍弃目标函数值下降最大的方向——这看似不合理的做法恰恰蕴含了合理的结果:放弃目标函数值下降最大的方向能更好地避免各方向线性相关。关于这一点,这里就不详述了。
一句话总结共轭方向法的过程:选定搜索方向d,使之满足共轭条件以及下降条件,在此搜索方向上通过精确线搜索确定移动的步长,然后将当前点移动到下一点,再重新选定搜索方向,周而复始,直到满足终止条件。
共轭方向法的收敛性:对二次函数,最多在n步(n为自变量的维数)内就可找到其极小值点。对一般的非二次函数,经适当修正后,也可以达到相同的效果。
共轭方向法的收敛速度:比最速下降法快,比牛顿法慢。
【4】共轭梯度法
注意:下面那些长长的推导过程,其实是有部分错误的,当年我认为我弄懂了,其实到了某个推导步骤以后,我就理解错了,只不过我以为我对了,我即将在另一篇文章里写上我认为正确的推导,对不住大家了...
“共轭梯度法”是一种特殊的“共轭方向法”。既然叫共轭梯度法,它与梯度必然是有关系的。共轭方向法与梯度也有关系——共轭方向法利用了目标函数的梯度信息(梯度与方向的积满足“下降”条件)。共轭梯度法与此关系有所区别:用当前点的负梯度方向,与前面的搜索方向进行共轭化,以得到新的搜索方向。
具体来说,这个新的搜索方向是怎么计算出来的呢?推导起来比较麻烦,下面就慢慢道来。
首先,需要说明共轭梯度法的一个理论基础(记为T1):在迭代过程中,我们会从初始点开始,在搜索方向上通过精确线搜索的方法,找到使目标函数值符合要求(例如,min f(X))的步长,然后将点移动到下一点。这样不断进行下去,就会得到很多个点。在N维空间Rn中,在每一个搜索方向上,都有无数个点,它们构成了一个轨迹(或者说一个集合),我们称之为线性流形——拿二维空间(二维平面)作比喻,就好像是一个点在二维平面上的移动形成的轨迹:
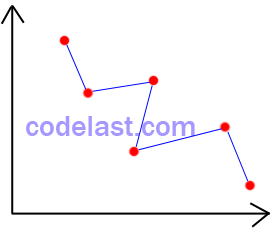
只不过在高维空间中,我们想像不出这个轨迹的样子,不过这没关系,能引申上去就好了。
当目标函数是二次函数时,在这个线性流形中,每一个我们迭代到的点都是极小值点。在某些书中,你可能还会看到一种说法,称此线性流形为N维超平面,也是一个意思,不过概念太多了会让人很晕,尤其是在没有掌握足够的背景的情况下,往往不能判断一个概念与另一个概念是不是同一个意思,这样就导致理解受到影响,因此,在刚开始学习的时候,我觉得努力弄懂一个概念就好了。
这个理论基础在推导“如何获取共轭梯度法的搜索方向”的过程中会用到。
由于上面的理论基础是在目标函数为二次函数的情况下得到的,因此,在推导共轭梯度法的搜索方向的公式之前,我们先假定目标函数是二次函数:
![]()
其中G为n阶对称正定矩阵。X为自变量(一个n维向量)。
如果觉得这个X为n维向量的函数形式有点怪的话,那么还是对比一下X为1维(可以视为一个标量)的函数形式,就很清楚了:
![]()
在下面的推导过程中,如果你遇到看上去很“别扭”的式子,只要按照这样的规则来对比就行了。
由于共轭梯度法就是与梯度相关的方法,因此我们必须要求[2]式的函数的梯度(即一阶导数):
![]()
现在,假设初始点为X0,我们从X0出发,先推导出前几个搜索方向的计算方法,从而总结出若干规律,进而再得到通用的公式。下面我们就开始这样做。
在每一个迭代点处,新的搜索方向都是用前面的搜索方向与当前点的负梯度方向共轭化得到的。在初始点处,并没有“前面的搜索方向”,因此,初始点处的搜索方向d0简单地定为负梯度方向:
![]()
上面的式子中,将目标函数在X0点的梯度g(X0)写为g0,是为了表达简洁。同理,g(X1)也记为g1,等等。
第二个迭代到的点为X1,它与X0满足关系:
![]()
这表明,点X1是在d0方向上,由X0点移动一定的距离得到的。移动的步长α0,则是通过精确线搜索的方法计算得到的,X1是一个极小值点,在点X1处,目标函数的一阶导数为零,即:
![]()
所以一阶导数再乘以d0仍然为零:
![]()
这个式子,在紧接着的推导中马上要用到。我发现从[7]到[8]我真的太废话了,好吧,我承认我很啰嗦…
既然第一个搜索方向d0毫无难度地取了负梯度方向,那么我们就来看看下一个搜索方向d1怎么获取。从共轭梯度法的定义(或者说是原则)——新的搜索方向是用前面的搜索方向与当前点的负梯度方向共轭化得到的——来看,d1与d0(前面的搜索方向)有关,也与-g1(当前点的负梯度方向)有关,因此,只需要假定d1是-g1与d0的线性组合即可:
![]()
其中,r0是一个实数。此外,由于每一个搜索方向与前面的搜索方向都是共轭的,因此,d1与d0还要满足共轭条件:
![]()
但是r0到底是什么值呢?只有知道了r0,我们才能算出d1,从而继续算出d2,d3,……
由上面的式[8],可以联想到,是否在式[9]的左右两边分别乘以一些矩阵或向量,从而得到一个等式,以求出r0?对,就是在式[9]的两边均左乘d0TG,可推出:
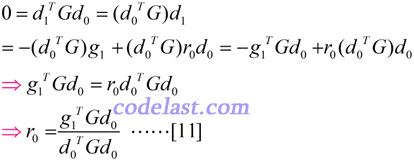
得到了r0,我们先记下它的形式,后面再使用。紧接着,来计算其他几个式子并由它们得到一些规律。
首先是在同一点处,搜索方向与梯度的点积dkTgk:

看出规律来了吗?dkTgk=-gkTgk?像这么回事。也就是说,在同一点处,搜索方向与梯度的点积等于负梯度与梯度的点积。所以我们估计d2Tg2,d3Tg3,……都是符合这个规律的。
其次是在某一点处的梯度与前面所有的梯度的点积gmTgn(m>n):
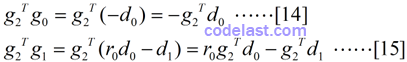
由前文所描述的共轭梯度法的理论基础T1,我们知道点X2,X3,……均为极小值点,因此,在这些点处,目标函数的梯度为零,即g(Xk)=0,所以有g2Td0=0,g2Td1=0,因此上面的[14],[15]式均为零:

又看出一点规律没有?gmTgn=0(m>n)?像是这么回事。也就是说,在某一点处的梯度与前面所有梯度的点积为零。
由上面的特例的计算,我们可以总结出一些规律并用这些规律来得到通用的结论了。假设对所有的搜索方向和梯度,有如下规律:
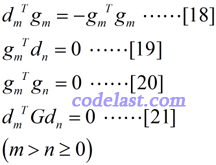
前面我们单独地求出了d0和d1,现在要来看方向d的通用的表达式怎么求了。可以设:
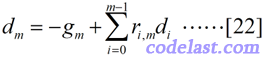
为什么可以这样表示方向d?乍一看,这个式子表示的含义是:当前点的搜索方向是当前点的负梯度方向与前面所有方向的线性组合——似乎很有道理,但是有什么理论依据可以让我们这样假设呢?其实,这是有线性代数理论支持的,但是这个证明涉及到更多的推导,所以这里就不扯过去了。前文所述的方向d1,也是这样假设之后再求出来的。我就是这样记忆的:当前点的搜索方向是当前点的负梯度方向与前面所有方向的线性组合。我觉得这种感觉很直观,并且也符合我心中的设想,而且事实上它也是对的,初学者就这样记住就好了。
[22]式不够直观,所以,我还是拿一个特例来演示:
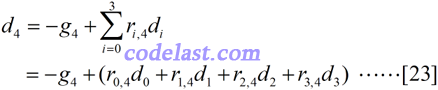
这下够清晰了吧?
但是,如何求出[22]式中的每一个ri,m呢?我们会想到,式子的左边是一个方向向量,在共轭梯度法中,我们要保证某一点的搜索方向与前面所有搜索方向是G共轭的,因此,这提醒了我们,应该在[22]式两边均左乘一个式子,形成“G共轭”的表达式——等式两边均左乘的式子就是dnTG(n=0,1,…,m-1):
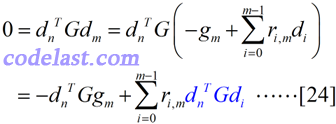
我认为在共轭梯度法的推导中,最令人费解的就是这个式子。恕我愚笨,我看了4本最优化的书才搞懂,每一本书不是这里略过去了,就是那里略过去了,总有让人坐过山车的跨越感,但想明白之后的感觉终究是很舒坦的,我在这里就要把它彻底写明白了。
首先要对一个概念非常清楚:在[24]式中,我们乘的dnTG,不是说我们要乘n个式子,而是说,对[22]式来说,当m选定以后,那么n就唯一选定了。例如,当m=4时,[22]式就是用来求d4的,此时,我们乘的dnTG就是d3TG:
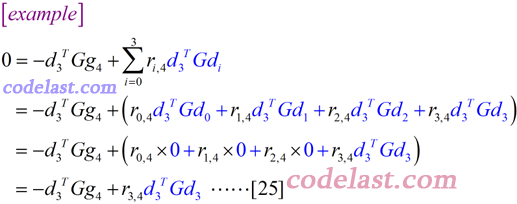
写得如此详细的一个例子,看懂了吗?从这个例子中,我们知道,对n所取的任何值,在[24]式的求和式∑中,除最后一项外,其余所有项的值均为0——这是因为任何一个方向与前面所有方向都是G共轭的(参看G共轭的定义)。所以现在可以写出[24]式的结果了:
![]()
其中,r的写法很不直观——其实,对每一个方向d来说,[25]式中只含有一个r,不会像[24]式那样,由于有多个r,使得必须要用复杂的下标来区分,因此此处我们完全可以用rn来代替[25]式中那个怪怪的r的表达式:
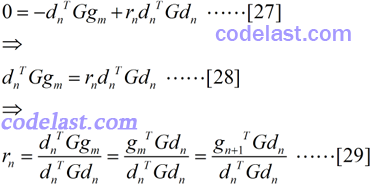
顺便将[27]式转换了一下,得到了[29]式,即 r 的计算方法——这就是我们日夜思念的式子啊,终于揭开面纱了!
(待补全)
共轭梯度法同样会有这样的问题:经过n步迭代之后,产生的新方向不再有共轭性。所以在实际运用中,也有很多修正方向的策略。其中一种策略是:经过n步迭代之后,取负梯度方向作为新的方向。
共轭梯度法的收敛性:比最速下降法的收敛性要好得多。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):

非常感谢,看了楼主的文章感觉节省了很多时间,还理解的比较到位。
真搞不懂那些写书的为啥把简单问题复杂化,我要是以后写书,肯定只写最核心的东西,其他相关的内容放备注供大家查阅。
最近在搞绿屏抠像的技术,用到共轭梯度下降,一直看的似懂非懂的,看了大大的感觉脑子清晰了很多,非常感谢!以后我也想做个类似的博客,分享一些自己的心得
[7]式有错误吧?在确定步长的时候,是要找到使f最小的α,所以要对α一阶导数=0,而梯度是对x的偏导,所以应该不错在这个等式吧?
我觉得错在此处
不错,被最优化考试累得焦头烂额的,只知道每个算法的步骤,但不知所以然,特意来拜读,感受颇深
楼主的最优化系列写得真心好!请问楼主当年学最优化时都看了哪些书?能否推荐几本好的最优化的书,本人最近也在自学最优化!谢谢啦!
没书可推荐。我看的比较杂,每本书一部分。我觉得几乎所有最优化的书都是写给“学霸”看的,所以我看起来觉得很难受,所以才写了这些总结的文章,试图能从另一个角度解释难懂的最优化世界。
关于共轭方向的,如公式10,右边d0的转置上标 T 应该是不需要的吧?
写的太好了!!上课听老师英文讲的半懂不5懂的.看完全懂了!
博主你好:
文章写得很好,正在拜读中,感觉受益良多,发现一个小问题:
本文第2节 牛顿法 最后
‘最速下降法的收敛速度:二阶收敛。因此,它比最速下降法要快。’
这句话是不是应该改成:‘牛顿法的收敛速度’呢
已修改,谢谢指正
牛顿法里关于G_k求导的公式里,多了个上标2.
感谢指正
牛顿法中:
"由于极小值点必然是驻点,而驻点是一阶导数为0的点,所以,对 r(X) 这个函数来说,要取到极小值,我们应该分析其一阶导数。对X求一阶导数,并令其等于0:"
下面的式子等号左边是一阶梯度.
另外, 二阶梯度和hessian不同, 如果这么写, 最好说明一下.
感谢博主,好文!
博主写得非常好,能否把CMA-ES给详细讲讲!非常感谢!
自适应协方差矩阵进化策略(Covariance Ma-trix Adaptation Evolution Strategy,CMA-ES)是Nikolaus Hansen等人在ES算法基础上发展起来的一种新型全局优化算法——网上搜到的,不过我真不懂...
谢谢博主,写的很详细。