现在有很多开源的中文分词器库,如果你的项目要选择其一来实现中文分词功能,必然要先评测它们的分词效果。如何评测?下面详细叙述。
【1】黄金标准/Golden standard
因此,要找有权威的分词数据来做为黄金标准。
大家可以使用SIGHAN(国际计算语言学会(ACL)中文语言处理小组)举办的国际中文语言处理竞赛Second International Chinese Word Segmentation Bakeoff(http://sighan.cs.uchicago.edu/bakeoff2005/)所提供的公开数据来评测,它包含了多个测试集以及对应的黄金标准分词结果。
文章来源:http://www.codelast.com/
【2】评价指标
精度(Precision)、召回率(Recall)、F值(F-mesure)是用于评价一个信息检索系统的质量的3个主要指标,以下分别简记为P,R和F。同时,还可以把错误率(Error Rate)作为分词效果的评价标准之一(以下简记为ER)。
直观地说,精度表明了分词器分词的准确程度;召回率也可认为是“查全率”,表明了分词器切分正确的词有多么全;F值综合反映整体的指标;错误率表明了分词器分词的错误程度。
P、R、F越大越好,ER越小越好。一个完美的分词器的P、R、F值均为1,ER值为0。
通常,召回率和精度这两个指标会相互制约。
例如,还是拿上面那句话作为例子:“科学技术是第一生产力”(黄金标准为“科学技术 是 第一 生产力”),假设有一个分词器很极端,把几乎所有前后相连的词的组合都作为分词结果,就像这个样子:“科学 技术 科学技术 是 是第一 第一生产力 生产力”,那么毫无疑问,它切分正确的词已经覆盖了黄金标准中的所有词,即它的召回率(Recall)很高。但是由于它分错了很多词,因此,它的精度(Precision)很低。
因此,召回率和精度这二者有一个平衡点,我们希望它们都是越大越好,但通常不容易做到都大。
文章来源:http://www.codelast.com/
为了陈述上述指标的计算方法,先定义如下数据:
 :黄金标准分割的单词数
:黄金标准分割的单词数
 :分词器错误标注的单词数
:分词器错误标注的单词数
 :分词器正确标注的单词数
:分词器正确标注的单词数
则以上各指标的计算公式如下:
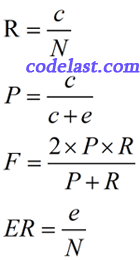
【3】正确及错误标注的计数算法
和 是按如下算法来统计的: 有了上面的算法,就很容易写出一个评测程序了。这里就不把程序放上来了。
文章来源:http://www.codelast.com/
【4】参考文献
① Word Segmentation: Quick but not Dirty.
② Chinese Segmentation and New Word Detection using Conditional Random Fields
Fuchun Peng, Fangfang Feng, Andrew McCallum, Computer Science Department, University of Massachusetts Amherst, 140 Governors Drive, Amherst, MA, U.S.A. 01003, {fuchun, feng, mccallum}@cs.umass.edu
③ A Compression-based Algorithm for Chinese Word Segmentation
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):

在垃圾邮件分析中,似乎也用到了分词技术
发现你最近写了很多文章嘛,步入正轨了嘛
多动动笔总是有好处的么