写这篇文章的过程中,我改稿改到怀疑人生,因为有些我自己下的结论在看了很多次源码之后又自我否定了多次,所以这篇文章花了我很长时间才完工。虽然完稿之后我仍然不敢保证绝对正确,但这至少是在我当前认知情况下我“自以为”正确的版本了,写长稿不易,望理解。
查看关于 rlpyt 的更多文章请点击这里。
rlpyt 是BAIR(Berkeley Artificial Intelligence Research,伯克利人工智能研究所)开源的一个强化学习(RL)框架。我之前写了一篇它的简介。
在单机上支持丰富的并行(Parallelism)模式是 rlpyt 有别于很多其他强化学习框架的一个显著特征。rlpyt可以使用纯CPU,或CPU、GPU混合的方式来并行执行训练过程。
▶▶ rlpyt的sampler模块概览
rlpyt有一种叫做“Sampler”的模块,我们姑且称之为“采样器”,它用于采样/收集agent与environment交互的数据,对于不同的训练模式(串行、并行、异步),rlpyt有不同的sampler实现:
├── async_│ ├── action_server.py│ ├── alternating_sampler.py│ ├── base.py│ ├── collectors.py│ ├── cpu_sampler.py│ ├── gpu_sampler.py│ └── serial_sampler.py├── base.py├── buffer.py├── collections.py├── collectors.py├── parallel│ ├── base.py│ ├── cpu│ │ ├── collectors.py│ │ └── sampler.py│ ├── gpu│ │ ├── action_server.py│ │ ├── alternating_sampler.py│ │ ├── collectors.py│ │ └── sampler.py│ └── worker.py├── serial│ ├── collectors.py│ └── sampler.py
直观感受:串行(serial)模式的sampler代码最简单,并行(parallel)模式下的cpu并行实现比gpu并行实现简单一些,异步(async_)模式下的实现最复杂。
不知道会不会有人好奇:为什么异步模式的module名是带下划线的async_而不是async呢?因为async在Python 3里是一个关键字,rlpyt的作者应该是为了避开这个问题才加了一个下划线。
文章来源:https://www.codelast.com/
在前面的系列源码分析文章中,我已经分析过了串行(serial)模式下的sampler代码,本文想分析的是并行(parallel)模式下的CPU并行实现代码,也就是树形图里的这一部分:
├── cpu│ ├── collectors.py│ └── sampler.py
文章来源:https://www.codelast.com/
▶▶ CPU sampler概览
CPU sampler的实现类是 CpuSampler,一级级向上,有多个父类:
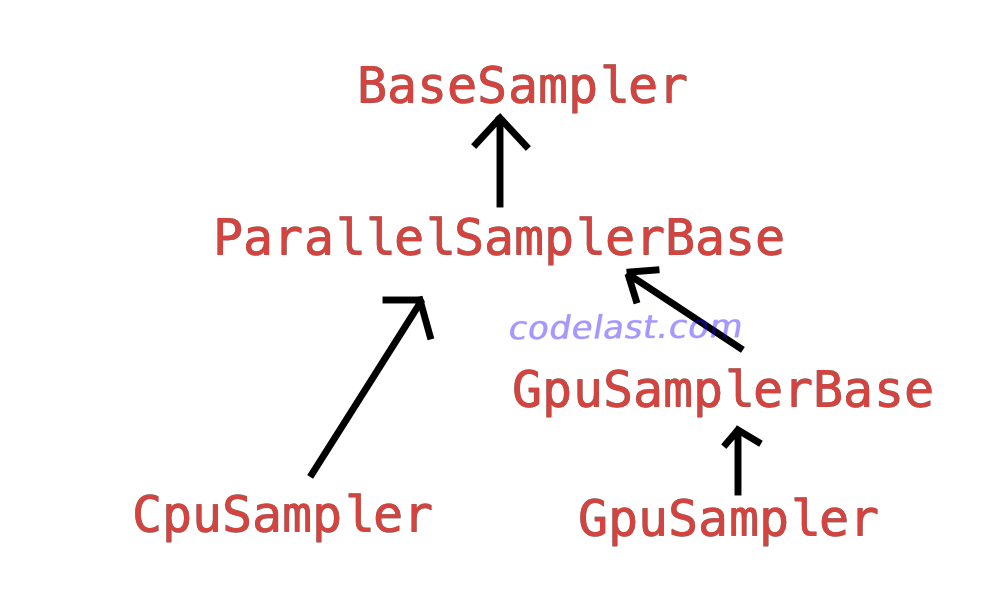
这个BaseSampler,同时也是 GpuSampler 的最顶级父类。
文章来源:https://www.codelast.com/
前面的文章已经讲过,sampler是collector外面包装的一层,真正去做数据收集工作的是collector类。对 CpuSampler 来说,它对应的collector代码实现在collectors.py中,里面包含多个collector类:CpuResetCollector,CpuWaitResetCollector,CpuEvalCollector等。
所以应该从两条线来分析sampler class,一条线是 CpuSampler→ParallelSamplerBase→BaseSampler,另一条线是collector class。为了不让篇幅过长,本文只分析第一条线,把collector class留到后面的文章。
▶▶ BaseSampler:一个主要用于定义各种接口的父类
最顶层的父类BaseSampler主要定义了各种接口,很多函数都没有实现:
def initialize(self, *args, **kwargs): raise NotImplementedError def obtain_samples(self, itr): raise NotImplementedError # type: Samples def evaluate_agent(self, itr): raise NotImplementedError def shutdown(self): pass
而__init__()函数还是像之前见识过的套路一样,使用save__init__args()来把可变参数保存到对象属性里:
save__init__args(locals())
其余就没啥好说的了。
文章来源:https://www.codelast.com/
▶▶ CpuSampler:主要充当一个入口
CpuSampler类的代码相当少,它主要充当一个入口,而不是实现主要逻辑:
class CpuSampler(ParallelSamplerBase): def __init__(self, *args, CollectorCls=CpuResetCollector, eval_CollectorCls=CpuEvalCollector, **kwargs): # e.g. or use CpuWaitResetCollector, etc... super().__init__(*args, CollectorCls=CollectorCls, eval_CollectorCls=eval_CollectorCls, **kwargs) def obtain_samples(self, itr): self.agent.sync_shared_memory() # New weights in workers, if needed. return super().obtain_samples(itr) def evaluate_agent(self, itr): self.agent.sync_shared_memory() return super().evaluate_agent(itr)
其中,obtain_samples() 用于采样一批数据,evaluate_agent() 用于评估agent——或者说是评估模型,差不多的意思。
这两个函数都调用父类ParallelSamplerBase的同名函数来实现对应功能,后面会在其他文章里具体分析。
在这两个函数的开头,都有一个 self.agent.sync_shared_memory() 的操作,这是干嘛?
其功能是:在并行模式下,采样/评估之前先同步shared model。
sync_shared_memory() 函数的实现是:
def sync_shared_memory(self):
if self.shared_model is not self.model:
self.shared_model.load_state_dict(strip_ddp_state_dict(
self.model.state_dict()))
这里的意思是:当 self.model 被训练过之后,可能已经和 self.shared_model 不是一个东西了,此时需要把 self.model 的参数copy到 self.shared_model 里。
strip_ddp_state_dict()函数是一个很tricky的操作,为什么从 self.model 取出来的 state_dict 不能直接用 load_state_dict() 加载到 self.shared_model 里呢?关于这一点,我觉得代码的注释里写得比较清楚,建议直接去看它。
这里就产生了两个问题:✓ 什么是shared model? ✓ 为什么要同步shared model?
文章来源:https://www.codelast.com/
▶▶ 什么是shared model
从名字上猜测,shared model就是一个“共享的模型”,之所以会有“共享”这个概念,是因为在多个进程中都需要使用模型,所以才需要“共享”。
✔ rlpyt在并行(parallel)模式下,会产生多个“worker”跑在多个进程里,这些worker会各自在environment中采样,采样得到的数据用于优化模型。
✔ worker在采样的时候会选择action,此时会用模型来做action selection。
✔ 所有worker关联到同一个agent对象(agent包含了策略网络的参数),只有一个进程会去做优化模型(也就是反向传播之类)的工作,这一点要特别注意,是一个进程,而不是所有worker进程!
✔ 在每个agent对象内部,会有一个类型为 torch.nn.Module 的 self.model 对象,还有一个 self.shared_model 对象,我们可以从agent的父类 BaseAgent 的__init__()函数中看到这一点:
def __init__(self, ModelCls=None, model_kwargs=None, initial_model_state_dict=None): save__init__args(locals()) self.model = None # type: torch.nn.Module self.shared_model = None
在agent对象初始化的时候,即在 BaseAgent.initialize() 函数中,会把 self.shared_model 初始化成和 self.model 一样:
def initialize(self, env_spaces, share_memory=False, **kwargs): """In this default setup, self.model is treated as the model needed for action selection, so it is the only one shared with workers.""" self.env_model_kwargs = self.make_env_to_model_kwargs(env_spaces) self.model = self.ModelCls(**self.env_model_kwargs, **self.model_kwargs) if share_memory: self.model.share_memory() self.shared_model = self.model
上面代码中的 if share_memory 这个条件是否得到满足呢?
在并行模式下,也就是从 ParallelSamplerBase._agent_init() 函数的代码我们可以发现,agent初始化的时候 share_memory 参数被设置成了 True:
agent.initialize(env.spaces, share_memory=True, global_B=global_B, env_ranks=env_ranks)
所以 if share_memory 的条件是满足的。
文章来源:https://www.codelast.com/
如果使用GPU训练模型,那么rlpyt会把model挪到用户指定的设备上,而shared_model需要放在CPU上(经查,PyTorch的Tensor或模型参数也是可以放在GPU上共享的,但有一些容易出错、需要谨慎处理的细节,所以我猜由于这个原因,作者选择了把shared_model放在CPU上),因此,这里创建出来了一个self.shared_model,用来防止之后self.model有可能被挪到GPU的情况发生——如果发生了,self.shared_model这个放在CPU上的模型才是多个进程间的共享模型。
那么这个shared_model在CpuSampler中真的有用吗?下面我们就一层层地挖下去,看看这个东西到底有没有用。
文章来源:https://www.codelast.com/
▶▶ 为什么要同步shared model
先说结论:在CpuSampler里,完全不需要同步。
为了确认这个结论,我们看看在使用CPU sampler的时候,BaseAgent类里的 self.shared_model 到底用在了什么地方。通过搜索代码,发现除了 sync_shared_memory() 函数之外,只有两个地方在用:
1、上面提到的 BaseAgent.initialize() 函数。在这里,对 self.shared_model 只有赋值操作,没有使用。
2、to_device() 函数:
def to_device(self, cuda_idx=None): if cuda_idx is None: return if self.shared_model is not None: self.model = self.ModelCls(**self.env_model_kwargs, **self.model_kwargs) self.model.load_state_dict(self.shared_model.state_dict()) self.device = torch.device("cuda", index=cuda_idx) self.model.to(self.device)
在这一段代码中,当使用CPU sampler时,cuda_idx 为 None,因此直接return了,self.shared_model 根本触达不到。
此外,BaseAgent的其他所有使用 self.shared_model 的地方,都是和异步(async_)模式相关的,和并行(parallel)模式无关。
因此,对CpuSampler来说,shared_model没用,不需要调用 sync_shared_memory() 来同步shared_model。
文章来源:https://www.codelast.com/
▶▶ shared model在什么情况下有意义
对CpuSampler来说,BaseAgent里的 self.model 对各个采样的worker来说都会实时更新,在action selection的时候使用的也是 self.model,而不是 self.shared_model,所以 shared_model 对CpuSampler来说其实没有意义。
但在其他模式下 shared model 还是有意义的,而且机制更复杂。
文章来源:https://www.codelast.com/
这一节就到这,且听下回分解。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):
