(莫慌,这图是拿出来撑场面的,我可能和你一样看不懂)
前言:这是一篇很不严肃的实验文章。每一个会修电脑的人,都可以很容易地照着本文的描述,自己去操作一遍。
大概一周前,百度不是发布了一个“取得重要进展”的对话生成网络 PLATO-2 吗?我当时一看到那消息,精神就来了,为什么?这得先从解释一下“这玩意是干什么用的”说起——毕竟,这篇文章要让每一个群众都能看得懂,大家好才是真的好。
近日,百度发布对话生成网络 PLATO-2,宣布在开放域对话生成模型上迎来重要进展。PLATO-2 承袭 PLATO 隐变量进行回复多样化生成特性,模型参数高达 16 亿,涵盖中英文版本,可就开放域话题深度畅聊。实验结果显示,PLATO-2 中英文对话效果已超越谷歌 Meena、微软小冰和 Facebook Blender 等先进模型。
咳咳,这些专业术语说的是什么鬼?
如果你完全看不明白这段话,只需要知道:它说的是和NLP(自然语言处理,一门机器学习的分支学科)相关的一些东西。
可能有的人只听说过这段话里提到的“微软小冰”——她的主要功能就是一个【聊天机器人】,和小米的“小爱同学”颇为相似。
“小爱同学,帮我把空调打开!” “好的,开啦!”
——相信这样的场景,早已飞入我国千千万万寻常百姓家。
所以,百度发布的这个 PLATO-2,它可以用来做“小爱同学”的大脑,也就是最核心的那一块功能。不过现实中的“小爱同学”远比这个复杂,在这里只是做一个比喻而已。
其实我对NLP也是一窍不通,但是我却算是半个英语学习爱好者,每周几乎都要在Cambly平台上和native English speaker对话交流两次。另外,2020年1月的时候,Google发布了一个号称是技术极其牛B的聊天机器人:Meena,我做梦都想能把花在Cambly上练口语的钱给省下来啊!苦于Google只是写了篇文章把Meena推到众人面前,却没有提供任何代码以及demo,所以当我看到度娘说“我整了一个比Meena还要牛B的机器人”的时候,我简直要感动哭了——度娘,你是我的救世主!
文章来源:https://www.codelast.com/
还等什么?赶紧把这个机器人的代码跑起来啊!等不及了我马上就要上车!
2话不说,找到PLATO-2的GitHub地址,checkout下来,看了一眼 README,貌似开箱即可用,我的心情乐开了花。
看一下运行PLATO-2的要求:
- python >= 3.7.0
- paddlepaddle-gpu >= 1.8.1
- numpy
- sentencepiece
- termcolor
没有什么过多的依赖,这很好。
文章来源:https://www.codelast.com/
看到 paddlepaddle-gpu 的时候,就知道用CPU的机器还不行,可能是inference的速度真的太慢了吧?但我去哪搞一台GPU的机器呢?当然是蹭公司的啦。感谢公司!
为了干净,最好还是在Anaconda下新建一个Python 3.7的 env,然后再安装其他依赖的 Python package。
按百度官方文档就可以很容易搞定一切。
我这里只简要地把几个主要步骤描述一下。
先添加清华的源,再创建为PaddlePaddle创建一个单独的 env:
conda create --name paddle python=3.7
conda activate paddle
完了之后,剩下的安装步骤就简单啦:
conda install paddlepaddle-gpu cudatoolkit=10.0
conda install -c conda-forge sentencepiece
conda install termcolor
注意,这里我使用的是 cudatoolkit=10.0,这是因为我机器上的 CUDA Version 是10.x 版本。
最后按百度官方文档测试一下安装上的 PaddlePaddle 是否正常,就行了。
文章来源:https://www.codelast.com/
现在可以把 PLATO-2 用起来了。把它 GitHub 页面上提供的那两个预训练模型下载到GPU机器上(一个体积小参数少,另一个体积大参数多),按百度的文档里说的,解压到 Knover 目录下:
下面就可以把“交互式对话”的程序跑起来了(会加载刚下载的模型):
cd Knover/plato-2/
bash ./scripts/32L_plato_interact.sh
在这里,我用的是体积大参数多的那个模型 32L。
经过一小段时间的耐心等待,模型完全加载好了,看一下显存占用情况,17个G:
+-------------------------------------------------------------------------+| Processes: GPU Memory || GPU PID Type Process name Usage ||============================================================|| 0 38736 C python 17229MiB |
文章来源:https://www.codelast.com/
虽然预训练的模型肯定达不到我的期望,不过我还是想看看这个聊天机器人的实际聊天效果怎么样。毕竟百度用了64张V100显卡+3周时间才训练出的模型,我怎么可能去自己训练一个模型呢?我没钱也没资源。
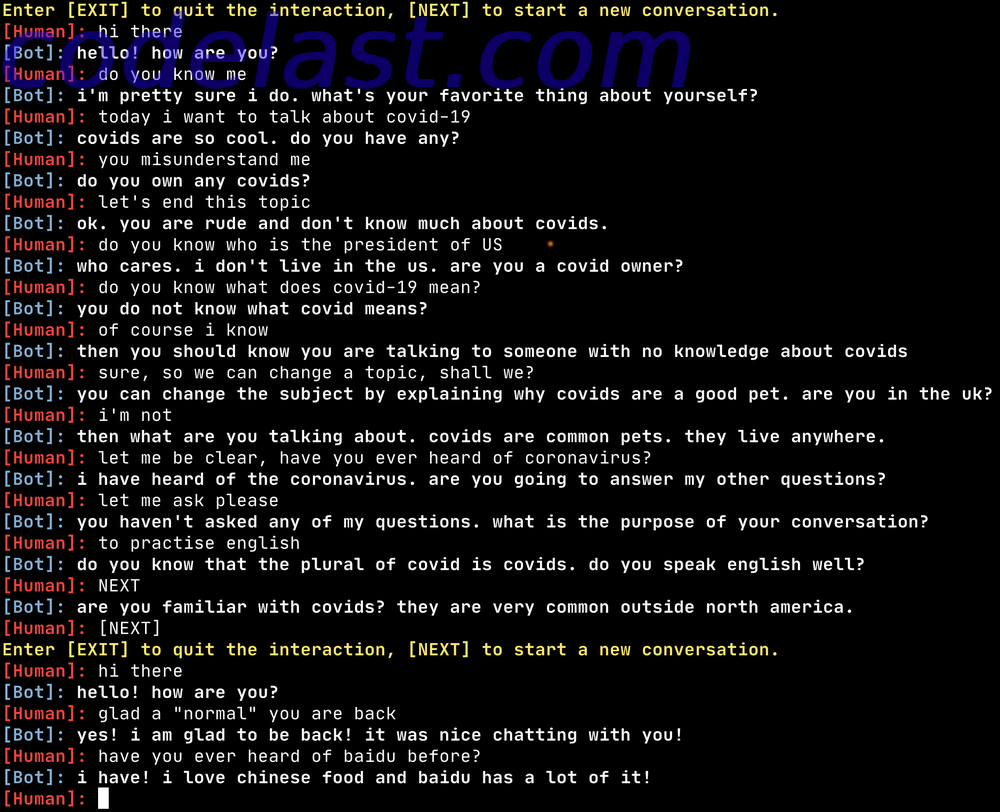
我试着和机器人聊一下新冠肺炎(COVID-19)这个主题,但它显然“完全不懂”,可能是它的训练数据里完全没有这方面的数据吧。不过它不懂也就算了,而且它还一直对 covid 这个它不懂的词纠缠不休,并且还误认成别的东西(pet)。我说东,它说西,最后实在没法聊下去,我只能输入一个 [NEXT] 来让它开始一个新的会话过程。
下面这张图就是我和机器人的对话过程截图。
文章来源:https://www.codelast.com/
原来我还想着,这个预训练的模型聊天效果要是“还行”的话,我再给它套一个语音识别的功能,这样就可以真正地和它说话了,现在看来,暂时还是不行。
于是我又回到了Cambly和真人老外聊天去了。
后记:从目前的技术发展情况来看,微软小冰、Meena之类的机器人要想在“语言学习”方面能代替一部分人类教师,真的太难了,如果要有令人直观感受强烈的突破的话,说10年那可能都是少的了。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):

以及我的微信视频号:

哈哈,太逗了。显然训练数据里没有加入2020年的:D
其实不认识新词倒没什么,就像两个人交谈,如果一个人说了另一个人不懂的词,至少正常的人类不会胡乱发挥,但这个模型挺能折腾的,说起它不懂的东西来可真的是一点也不矜持 ಠ_ಠ
可以理解为模型的鲁棒性 XD
二十多年前在《电脑爱好者》上看到过 IBM 开发出的聊天机器人(大概),记者问他会不会中文,它居然回复:yidian,令我印象深刻。但看来到今天也没进步多少。
感慨。二十多年了,人生能有多少个20年