下面是一些未归类的命令及操作方法,专门记在此文中,以便将来查询。由于文章较长,请用Ctrl+F查询关键字来定位到你需要的内容。
(1)关于html的tagName:
IHTMLElement::get_tagName方法可获取元素的tagName。tagName指的是元素的标签名。直观的效果测试,请看【这个】链接。
(2)在IWebBrowser2中执行Javascript:
获得了IWebBrowser2指针
(假设为:
IWebBrowser2 *pWB
)
后,可以通过这样的方法控制执行Javascript语句:
IHTMLDocument2* pDoc = NULL;
IDispatch *pDisp = NULL;
pWB->get_Document(&pDisp);
HRESULT hr = pDisp->QueryInterface(IID_IHTMLDocument2, (void**)&pDoc);
if (pDoc)
{
IHTMLWindow2* pWin2 = NULL;
pDoc->get_parentWindow(&pWin2);
if (pWin2)
{
CString strJS = _T("alert('Hello');"); // JS语句
CComBSTR bstrJS = strJS.AllocSysString();
CComBSTR bstrLanguage = SysAllocString(L"javascript");
VARIANT varRet;
pWin2->execScript(bstrJS, bstrLanguage, &varRet); // 执行
}
}
(3)禁止crontab的Email提醒:
crontab在执行了一个任务后,可能会发邮件给root用户,如何禁止它?你只需要把你在crontab中写的命令后面加上重定向即可:
>/dev/null 2>&1
(4)error while loading shared libraries: libiconv.so.2: cannot open shared object file: No such file or directory:
编译完PHP后,make install时出现这个错误提示,解决办法为:在文件 /etc/ld.so.conf 中添加一行:
/usr/local/lib
然后执行命令:
/sbin/ldconfig
然后再make install,不再出错。
(5)想要进入MySQL命令行时,提示错误:mysqladmin: connect to server at 'localhost' failed error: 'Access denied for user 'root'@'localhost' (using password: NO)':
mysql -u root -p
然后输入密码之后,出现了上面的错误,此时,我们就来重置MySQL的密码吧:
先停掉MySQL服务:
service mysqld stop
然后执行以下命令:
mysqld_safe --skip-grant-tables &
接着输入:
mysql -uroot -p
并回车,就进入了MySQL命令行,然后再利用以下MySQL命令,将MySQL的密码重置:
>use mysql;
> update user set password=PASSWORD("your_new_password") where user="root";
> flush privileges;
> quit
其中,your_new_password 就是你要设置的新密码。
(6)RHEL 5.3下,编译安装PHP时的几个错误:
①configure的错误:“……apxs: No such file or directory”
apxs是做什么用的?编译PHP时应该有这个参数:--with-apxs2=
此参数的作用是整合PHP与Apache,而configure时找不到apxs的原因是你没有安装Apache的devel库。装上之后再configure就无问题了。
②configure的错误:“……is not a FreeTDS installation directory”
这是因为你添加了编译参数:
--with-mssql=
如果你的PHP需要连接MS SQL Server,则需要FreeTDS库,否则,将这个编译参数去掉即可。
③make的错误:“undefined reference to `libiconv_open'”
这个有点雷人,在libiconv已经安装了的情况下,make的时候仍然出现这种错误,给人找不到库文件的错觉。事实上,它恰恰是由于库文件“过多”造成的,以至于PHP编译的时候不知道使用哪个文件。查找系统中的 iconv.h 文件,你应该会发现多个版本,它们可能是由不同版本的安装包装上去的,所以,你可以选择卸载其中的一些包,剩下一个即可。当然,有一种更方便的办法:把其中的一部分 iconv.h 重命名为其他名字,只剩下一个 iconv.h ,然后再对PHP进行make,就可以顺利编译成功了。
(7)配置一台服务器无密码SSH登录另一台服务器:
假设你有两台服务器A、B,服务器B通过SSH命令登录服务器A时,需要输入密码,要配置成可以不输入密码就登录,需按下面的方法操作(这里的演示是针对root用户的):
在服务器B上,执行命令:
ssh-keygen -d
然后一路回车,不用输入任何内容。然后,你就会在 /root/.ssh/ 目录下看到了两个生成的文件:id_dsa 及 id_dsa.pub,将这两个文件拷贝到服务器A上(假设就放置在 /root/ 目录下),然后执行:
cat /root/id_dsa.pub >> /root/.ssh/authorized_keys
就搞定了,此时,从服务器B以SSH登录服务器A时,不再需要输入密码。
(8)如何在Linux shell命令行下输入tab键/制表符:
假设你有一个shell命令:
sed '10i\word like' -i /home/file.txt
这个命令的作用是:在文件 /home/file.txt 的第10行插入一句话:“word like”。其中,单词“word”和“like”中间的分隔符是tab键(制表符),那么如何输入它呢?直接按tab键或者输入 \t 来代替都是不行的。方法很简单:很按Ctrl+V键,然后放手,再按键盘上的tab键。如果你需要输入多个tab,那么你多次这样操作就可以了。
假设有变量:
A=3.87
要取整(不是四舍五入,而是去掉小数),可以这样输出:
echo ${A%.*}
输出结果为 3
(11)通过DNSPod的API(基于版本V2.8)停止一条域名记录的解析
如果你使用DNSPod的域名解析服务,并且你想通过其提供的API来停掉一条记录的解析的话,可以按如下过程来实现:
我们可以通过http请求,以POST方式向DNSPod的系统提交一个操作,你可以用任意编程语言完成这个过程。为了简单,这里向大家演示在Linux命令行下,通过 curl 命令是如何完成的。
首先,你要获取你的域名的ID,这里说的域名,是指类似于 abc.com 这样的东西,在DNSPod的系统中,它对应了一个ID(数字),我们先要获取这个ID,然后才能找到其中的一条记录(类似 于 test.abc.com 这样的东西)。
还要再插一句:在向DNSPod的系统提交操作时,要按“程序英文名/版本 (联系邮箱)”的格式设置 UserAgent 的信息(如果不按这个要求设置,请求有可能被拒绝),例如:
YourAppName/1.1(your_email@abc.com)
在 curl 中,可以通过 -A 参数来指定 UserAgent,通过 -d 参数来提交 POST 请求。
所以,我们获取域名ID的curl命令可以这样写:
curl -A "YourAppName/1.1(your_email@abc.com)" -d "login_email=your_email@abc.com&login_password=your_password&format=xml&type=mine" "https://dnsapi.cn/Domain.List"
其中,login_email,login_password,format,type的含义分别是:你登录DNSPod的用户名,登录DNSPod的密码,返回结果的格式,域名权限种类。
返回的结果为XML格式,你可以看到里面包含了你所有域名的信息,找到对应的域名,再提取出其中的<id></id>的值,就可以得到该域名的ID了。至于这个提取的过程怎么完成,你可以用正则表达式,也可以用多步shell字符串处理(grep等)来完成,如果你不嫌麻烦,还可以用C++程序来解析XML,这里我就不多说了。
在DNSPod的系统中,这个域名ID是永远不变的(只要你的域名不删掉重建),我们可以记录下来,在后面的步骤中写死就行了,没有必要每次都去获取,因为DNSPod API的响应速度实在不敢恭维(太慢了)。
得到了域名的ID,我们就可以获取它里面的一条记录的ID了。同理,我们的命令是:
curl -A "YourAppName/1.1(your_email@abc.com)" -d "login_email=your_email@abc.com&login_password=your_password&format=xml&domain_id=
123456789" "https://dnsapi.cn/Record.List"
注意这里由于排版的关系,我换了一个行,其实只有一行。其中,domain_id 就是在上一步中你获取到的域名ID,这里我是乱写的,仅作演示用,请自行修改为正确的值。
返回的结果为XML格式,你可以看到里面包含了该域名下所有记录的信息,找到对应的记录,再提取出其中的<id></id>的值,就可以得到该记录的ID了。
与上面所说的域名一样,该ID值是不变的(只要你不把这条记录删除重建),我们可以直接记下来,以后不再重复地去取它。
下面,就是如何停掉这条记录的解析的方法了。命令为:
curl -A "YourAppName/1.1(your_email@abc.com)" -d "login_email=your_email@abc.com&login_password=your_password&format=xml&domain_id=
123456789&record_id=5555555&status=disable" "https://dnsapi.cn/Record.Status"
注意这里由于排版的关系,我换了一个行,其实只有一行。
基本上不用再解释了。record_id 就是上一步中获取到的记录的ID,status为disable表示暂停解析这条记录(enable则为启用)。
返回结果为XML格式,类似于:
<?xml version="1.0" encoding="UTF-8"?>
<dnspod>
<status>
<code>1</code>
<message>Record status changed.</message>
<created_at>2010-12-22 16:20:15</created_at>
</status>
</dnspod>
查看其中的<code></code>段的值,如果为1则表示操作成功。
(12)COM中的客户、可连接对象、接收器对象、连接点对象之间的关系
用一张图表示(来自于网上,出处未知,感谢原作者):
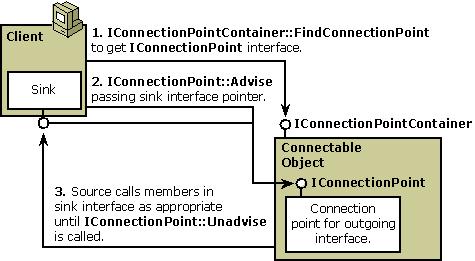
(13)用shell统计一个文件中的字符串个数
假设要统计文件 file.txt 中的字符串“Str[”(不含引号)的个数,可以这样做:
grep -o "Str$$!" file.txt | wc -l
(14)在MathType编辑器中输入空格
MathType是地球上最强大的数学公式编辑器,如果你要在里面输入一个空格的话,会发现直接按空格没有用。其实你只要按快捷键Ctrl+Alt+空格,就可以输入一个空格了。
(15)Linux下某一个用户对应的crontab文件在哪里
在RHEL中,如果你通过编辑 /etc/crontab 文件的方式来设置计划任务,它是不与某一个特定用户关联的(只不过你可以指定运行该命令的用户),但是用crontab -e命令来编辑计划任务的话,这是与当前用户相关的,并且默认是用vi编辑器来打开的,如果你要用其他编辑器来打开,可以直接编辑文件,例如,你的abc用户对应的crontab文件是:/var/spool/cron/abc
(16)mount一个ISO文件
mount -t iso9660 -o loop /home/XXX.iso /mnt/cdrom/
其中,/home/XXX.iso 就是你要mount的ISO文件。
(17)获取std::string数组的元素个数
假设你有如下的string数组:
std::string arr[] = {"abc", "111122223333", "@"};
那么,如何获取其中的元素个数呢(此处为3)?
这样做:
int n = sizeof(arr) / sizeof(string);
有人说,这个string数组中的每一个字符串的长度都不同,这样求出来的数对吗?对的。因为实际上数组arr中存储的只是三个指针,它们的实际内容(那些字符串)是存储在别的地方,sizeof(arr)不过是求出了这些指针所占的空间大小,再除以每一个指针所占的空间大小(sizeof(string)),就可以得知数组的元素个数了。
(18)cURLpp的编译安装
cURLpp 基于libcurl,所以要先安装 libcurl:
用源码方式安装 libcurl:
./configure --prefix=/usr/local/libcurl
make
make install
安装之后做符号链接,但先要删除系统中已经存在的旧版本的头文件目录:
mv /usr/include/curl /usr/include/curl.bak
再做符号链接:
ln -s /usr/local/libcurl/include/curl /usr/include/curl
同样要先删除系统中已经存在的旧版本的库文件:
mkdir -p /usr/lib/curl.bak/; mv -f /usr/lib/libcurl.* /usr/lib/curl.bak/
再做符号链接:
ln -s /usr/local/libcurl/lib/libcurl.so /usr/lib/libcurl.so
ln -s /usr/local/libcurl/lib/libcurl.a /usr/lib/libcurl.a
再安装curlpp:
./configure --prefix=/usr/local/curlpp
make
make install
编译的时候,要在Makefile中加上-lcurlpp和-lutilspp两个参数才能成功编译,添加了这两个参数后,虽然能通过编译了,但是可能还会看到以下两个警告信息(虽然不是错误):
①./include/cURLpp/curlpp/config.win32.h:64:1: warning: "STDC_HEADERS" redefined
在文件config.win32.h的64行左右,可见如下代码:
/* Define to 1 if you have the ANSI C header files. */
#define STDC_HEADERS
可见,注释处已经提示我们了,要改为以下代码:
#define STDC_HEADERS 1
②In file included from src/../include/cURLpp/curlpp/internal/../internal/global.h:28,
from src/../include/cURLpp/curlpp/internal/../Types.hpp:28,
from src/../include/cURLpp/curlpp/internal/OptionContainerType.hpp:31,
from src/../include/cURLpp/curlpp/internal/OptionContainer.hpp:29,
from src/../include/cURLpp/curlpp/Option.hpp:29,
from src/OrderFetcher.cpp:10:
./include/cURLpp/curlpp/config.win32.h:6:1: warning: "/*" within comment
在文件config.win32.h的第6行,可见如下注释:
/* DO NOT define or undefine this symbol if you are building from the IDE
可见此行没有结束注释符“*/”,所以添加上:
/* DO NOT define or undefine this symbol if you are building from the IDE */
(19)Linux shell下将标准输出和错误都重定向到文件
假设你编译一个程序:
make >& result.txt
这样就把标准输出和错误输出都重定向到了文件result.txt中。
(20)Linux下SVN的安装
我觉得下载源码包来安装是最好的方式。将源码包解压开来之后直接configure的话,通常会提示找不到apr的错误。APR是Apache的一个库:http://apr.apache.org/
下载APR 1.4.5,APR-util 1.3.12并安装——
先安装APR 1.4.5:
./configure --prefix=/usr/local/apr make make install
再安装APR-util 1.3.12:
./configure --prefix=/usr/local/apr-util --with-apr=/usr/local/apr make make install
然后再对SVN的源码包进行configure,要指明APR的路径:
./configure --prefix=/usr/local/subversion --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util --with-ssl
仍然会提示错误,这回提示的是找不到SQLite的错误。好吧,现在去下载SQLite的.tar.gz的源码安装包:http://www.sqlite.org/download.html
然后将源码包里,根目录下的sqlite3.c文件,拷贝到SVN源码包解压目录下的“sqlite-amalgamation”目录中(这个目录是不存在的,你要自己先手工创建)。至于SQLite,根本不需要去编译它,因为我们需要的,只是一个sqlite3.c文件而已。
还没完!现在还要安装neon这个库,不装的话,可能你在执行svn命令的时候,会得到以下错误:
Unrecognized URL scheme for ……
所以用源码安装包安装neon:
./configure --prefix=/usr/local/neon --with-ssl=openssl make make install
现在再次对SVN源码安装包进行configure,make,make install的过程,就可以顺利完成SVN的安装了:
./configure --prefix=/usr/local/subversion --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util --with-neon=/usr/local/neon --with-ssl
补充:SVN更新命令(将服务器上的文件更新到本地):svn update
文章来源:http://www.codelast.com/
(21)awk 统计文件中某一列的和(sum)
假设有文件 data.txt:
1.2 3.5
31 20.6
8.8 9.2
……
要统计第二列之和,可以这样做:
cat data.txt | awk '{print $2}' | awk 'BEGIN{sum=0}{sum+=$1}END{print sum}'
(22)用 vim 查看文档中的分隔符
进入命令模式,用set list命令即可,即:
:set list
(23)用Excel来生成一堆随机数
假设你要生成范围在0.1~2000之间的随机数:选中一个单元格,在上方的fx(函数填写处)写上:=RAND()*(2000-0.1)+0.1,就会看到这个单元格已经生成了一个随机数,然后再选中这个单元格,鼠标移动到其右下角的框,待鼠标变成十字形时,向下拖动,想要多少随机数就拖多少出来吧!
(24)指定 awk 的分隔符
awk 默认是会把TAB(制表符)和空格都当作分隔符的(混用),所以,如果你的一行数据中既含有空格,又含有TAB,不要以为awk只会按TAB来分割数据,其实它是按TAB和空格一起来分割的!这一点很重要,如果不注意的话,你可能会导致引用了错误的位置,例如有这样一行数据:
123[TAB]kuiaFWEF[空格]838241[TAB]SDFH
那么,变量 $3 代表的是“838241”,而不是“SDFH”!
如果要指定只使用TAB为分隔符,则应这样:
cat file.txt | awk -F "\t" '{print $3}'
文章来源:http://www.codelast.com/
(25)用 awk 查找不包含指定字符串的记录
假设一个文本文件data.txt有N行,要找出所有不含字符串“abc”的行,则:
awk '!/abc/' data.txt
(26)shell中构造一个数字序列(循环)
最可靠、直观的方式:
for((i=1;i<10000000;i++));
do
echo $i
done
如果用 for i in `seq 1 1000000`; 的方式,则有可能在 i 较大时出问题。
(27)统计一个文件中,某字符的个数
假设文件为file.txt,要统计的字符为“(”,则:
grep -o "(" file.txt | wc -l
据说某些版本的grep没有-o选项,这时就要采取其他的办法了。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):
