《Neural Networks and Deep Learning》一书的中文译名是《神经网络与深度学习》,书如其名,不需要解释也知道它是讲什么的,这是本入门级的好书。
在第一章中,作者展示了如何编写一个简单的、用于识别MNIST数据的Python神经网络程序。对于武林高手来说,看懂程序不会有任何困难,但对于我这样的Python渣则有很多困惑。所以我对做了一些笔记,希望同时也可以帮助有需要的人。
Algorithm
[原创] 用人话解释机器学习中的Logistic Regression(逻辑回归)
友情提示:如果觉得页面中的公式显示太小,可以放大页面查看(不会失真)。
Logistic Regression(或Logit Regression),即逻辑回归,简记为LR,是机器学习领域的一种极为常用的算法/方法/模型。
你能从网上搜到十万篇讲述Logistic Regression的文章,也不多我这一篇,但是,就像我写过的最优化系列文章一样,我仍然试图用“人话”来再解释一遍——可能不专业,但是容易看得懂。那些一上来就是几页数学公式什么的最讨厌了,不是吗?
所以这篇文章是写给完全没听说过Logistic Regression的人看的,我相信看完这篇文章,你差不多可以从无到有,把逻辑回归应用到实践中去。
[原创] 如何用「归纳假设法」求归并排序的时间复杂度
分析归并排序算法的时间复杂度,可以根据算法的逻辑,分析每一个步骤的最坏情况,然后得到总体的时间复杂度;也可以利用数学中的『归纳假设法』,用几乎纯数学的方式来得到它的时间复杂度。而后者比前者好理解得多,所以,我认为要推导归并排序的时间复杂度的话,归纳假设的方法是不二之选。
[原创] Shell sort(希尔排序)笔记
『1』概述
希尔排序(Shell sort)是一种不常用的排序算法,因为它效率不算高,但是作为插入排序的改进算法之一,有必要了解一下。
- 时间复杂度:
最坏情况: 
最好情况: 
平均情况: 
- 是不是稳定排序算法:否
- 得名起源:1959年的时候Donald Shell发明的,所以叫Shell sort
[原创] 再谈 梯度下降法/最速下降法/Gradient descent/Steepest Descent
当今世界,深度学习应用已经渗透到了我们生活的方方面面,深度学习技术背后的核心问题是最优化(Optimization)。最优化是应用数学的一个分支,它是研究在给定约束之下如何寻求某些因素(的量),以使某一(或某些)指标达到最优的一些学科的总称。
梯度下降法(Gradient descent,又称最速下降法/Steepest descent),是无约束最优化领域中历史最悠久、最简单的算法,单独就这种算法来看,属于早就“过时”了的一种算法。但是,它的理念是其他某些算法的组成部分,或者说在其他某些算法中,也有梯度下降法的“影子”。例如,各种深度学习库都会使用SGD(Stochastic Gradient Descent,随机梯度下降)或变种作为其优化算法。
今天我们就再来回顾一下梯度下降法的基础知识。
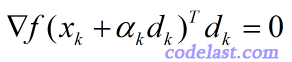


[原创]用“人话”解释不精确线搜索中的Armijo-Goldstein准则及Wolfe-Powell准则
line search(一维搜索,或线搜索)是最优化(Optimization)算法中的一个基础步骤/算法。它可以分为精确的一维搜索以及不精确的一维搜索两大类。
在本文中,我想用“人话”解释一下不精确的一维搜索的两大准则:Armijo-Goldstein准则 & Wolfe-Powell准则。
之所以这样说,是因为我读到的所有最优化的书或资料,从来没有一个可以用初学者都能理解的方式来解释这两个准则,它们要么是长篇大论、把一堆数学公式丢给你去琢磨;要么是简短省略、直接略过了解释的步骤就一句话跨越千山万水得出了结论。
每当看到这些书的时候,我脑子里就一个反应:你们就不能写人话吗?
[原创]漫谈line search中的Fibonacci搜索与黄金比例搜索
在一维搜索(line search)中,Fibonacci搜索与黄金比例搜索是一对“亲兄弟”,因为它们都是用分割区间的方法来求极小值,所以过程是相似的。本文就随意聊一下它们的区别与联系。
[原创]一维搜索中的划界(Bracket)算法
很多最优化算法需要用到一维搜索(line search)子算法,而在众多的一维搜索算法中,大多数都要求函数被限制在一个单峰区间内,也就是说,在进行一维搜索的区间内,函数是一个单峰函数。尽管有一些改进的一维搜索算法(例如  建议的一种改进过的黄金搜索算法)可以处理函数非单峰的情况,但是,在没有确定函数在一个区间内是单峰的之前,即使在搜索过程中,函数值持续减小,我们也不能说极小值是一定存在的,因此,找出一个区间,在此区间之内使函数是单峰的,这个过程是必需的(我更倾向于接受这种观点)。这个过程就叫作划界(Bracket)。Bracket这个单词是括号的意思,很形象——用括号包住一个范围,就是划界。在某些书中,划界算法也被称为进退法。
建议的一种改进过的黄金搜索算法)可以处理函数非单峰的情况,但是,在没有确定函数在一个区间内是单峰的之前,即使在搜索过程中,函数值持续减小,我们也不能说极小值是一定存在的,因此,找出一个区间,在此区间之内使函数是单峰的,这个过程是必需的(我更倾向于接受这种观点)。这个过程就叫作划界(Bracket)。Bracket这个单词是括号的意思,很形象——用括号包住一个范围,就是划界。在某些书中,划界算法也被称为进退法。
[原创]最优化/Optimization文章合集
最优化(Optimization)是应用数学的一个分支,它是研究在给定约束之下如何寻求某些因素(的量),以使某一(或某些)指标达到最优的一些学科的总称。我一直对最优化比较感兴趣,所以写过一些相关的笔记,可能有不正确的地方,但请学术派、技术流们多多包涵。
➤ 拟牛顿法/Quasi-Newton,DFP算法/Davidon-Fletcher-Powell,及BFGS算法/Broyden-Fletcher-Goldfarb-Shanno
➤ 最速下降法/steepest descent,牛顿法/newton,共轭方向法/conjugate direction,共轭梯度法/conjugate gradient 及其他
➤ 选主元的高斯-约当(Gauss-Jordan)消元法解线性方程组/求逆矩阵
文章来源:http://www.codelast.com/
➤ 关于 最优化/Optimization 的一些概念解释